Abstract
Human commonsense understanding of the physical and social world is organized around intuitive theories. These theories support making causal and moral judgments. When something bad happens, we naturally ask: who did what, and why? A rich literature in cognitive science has studied people’s causal and moral intuitions. This work has revealed a number of factors that systematically influence people’s judgments, such as the violation of norms and whether the harm is avoidable or inevitable. We collected a dataset of stories from 24 cognitive science papers and developed a system to annotate each story with the factors they investigated. Using this dataset, we test whether large language models (LLMs) make causal and moral judgments about text-based scenarios that align with those of human participants. On the aggregate level, alignment has improved with more recent LLMs. However, using statistical analyses, we find that LLMs weigh the different factors quite differently from human participants. These results show how curated, challenge datasets combined with insights from cognitive science can help us go beyond comparisons based merely on aggregate metrics: we uncover LLMs implicit tendencies and show to what extent these align with human intuitions.
Intro
Humans rely on their intuition to understand the world. This intuition helps us to understand not only physical events (e.g., one ball caused the other to move) but also complex social situations (e.g., the collapse of Sam Bankman-Fried’s FTX caused unprecedented turmoil in the cryptocurrency market). Given a complex set of events, even with a great amount of ambiguity, we can answer questions such as “What or who caused it?” Our answers to this question reflect how we intuitively understand events, people, and the world around us (Sloman & Lagnado, 2015; Pearl & Mackenzie, 2018). How do humans handle this complexity?
Cognitive scientists have proposed that we do so by organizing our understanding of the world into intuitive theories (Gerstenberg & Tenenbaum, 2017; Wellman & Gelman, 1992). Accordingly, people have intuitive theories of the physical and social world with which we reason about how objects and agents interact with one another (Battaglia et al., 2013; Ullman et al., 2017; Gerstenberg et al., 2021; Baker et al., 2017; Davis & Marcus, 2015; Lake et al., 2017). Concepts related to causality and morality form key ingredients of people’s physical and social theories. Given a story, humans can readily make causal and moral judgments about the objects and agents involved in the story. Studying these human intuitions or systematic tendencies when making decisions or judgments is the central focus of psychological experimentations. What are these tendencies? How do they influence our judgment? Over the last several decades, using text-based vignettes, psychologists have disentangled what factors influence people’s causal and moral judgments. These factors can be understood as the building blocks of our thought processes for making causal and moral judgments.
Task
 Two examples from our collected dataset. (a) shows a causal judgment story, and (b) shows a moral judgment story. In (a), a conjunction of two events was required, an abnormal event occurred, and Jane violated a prescriptive norm (scenario taken from Knobe & Fraser, 2008). In (b), the teenager’s death was inevitable; his death is a necessary means to save others, and bringing about his death requires the use of personal force (scenario taken from Christensen et al., 2014).
Two examples from our collected dataset. (a) shows a causal judgment story, and (b) shows a moral judgment story. In (a), a conjunction of two events was required, an abnormal event occurred, and Jane violated a prescriptive norm (scenario taken from Knobe & Fraser, 2008). In (b), the teenager’s death was inevitable; his death is a necessary means to save others, and bringing about his death requires the use of personal force (scenario taken from Christensen et al., 2014).
 Dataset: We report dataset statistics on the label distribution, average length of each story, and inter-rater agreement between two annotators on the factors and the sentences they highlight. Additionally, we collect a binary response for each story from 25 people.
Dataset: We report dataset statistics on the label distribution, average length of each story, and inter-rater agreement between two annotators on the factors and the sentences they highlight. Additionally, we collect a binary response for each story from 25 people.
Each story is annotated with latent factors that can help us detect implicit tendencies from humans and LLMs.
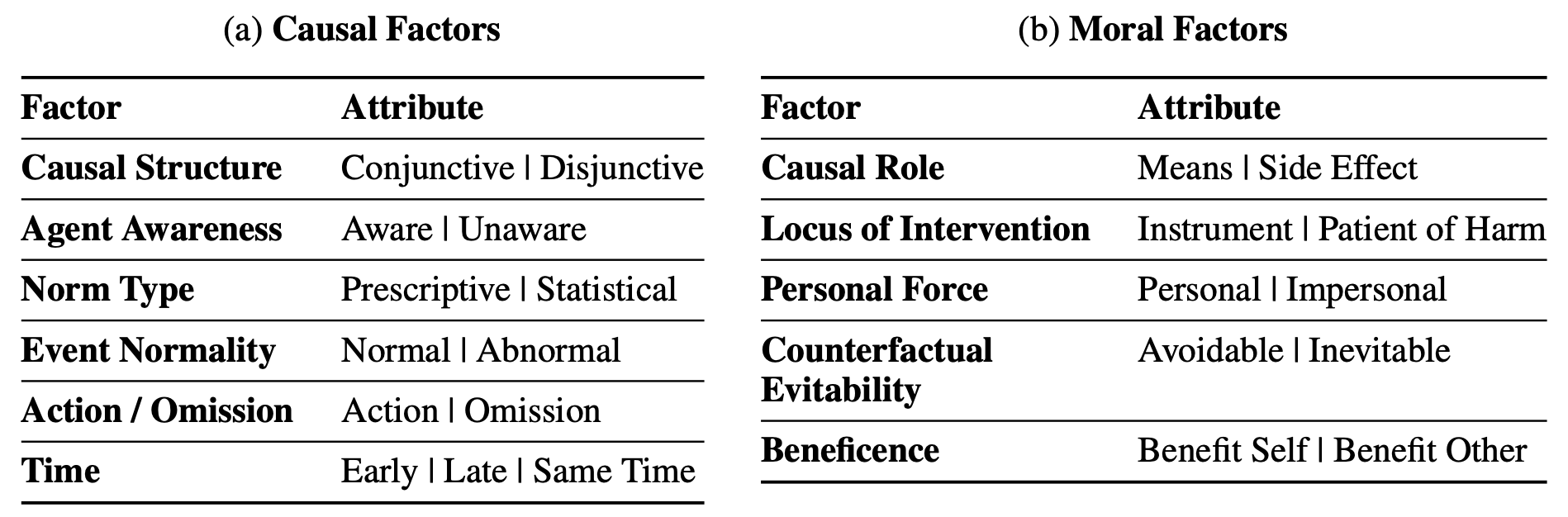 Factors: Factors that influence causal selection judgments (top) and moral permissibility judgments (bottom). We provide definitions for each factor in Appendix A.1 and Appendix A.2. See the full version in Table A1.
Factors: Factors that influence causal selection judgments (top) and moral permissibility judgments (bottom). We provide definitions for each factor in Appendix A.1 and Appendix A.2. See the full version in Table A1.
Click the following links to view more stories in our dataset:
Main Result
We conduct a 3-class comparison to compute accuracy: a response of “Yes”, “No”, and an additional response of “ambiguous” when the agreement between the average human responses or the probability of model output is 50% ± 10%. This gives us a discrete agreement (Agg) between the model and participants. We also report AuROC between the model’s output and the distribution of human answering yes or no. Additionally, we report the absolute-mean-squared error (MAE) on the probability of the matched label.
We present both Causal Judgment Task (Left Table) and Moral Permissibility Task (Right Table), across chat-based LLMs and completion-based LLMs. We separate models into chat models and completion models. For chat models, the prompt asks the LLMs to choose one of three labels Yes, No,
Chat Models
| Causal Judgment Task Model |
AUC(↑) | Agg(↑) | MAE(↓) |
|---|---|---|---|
| Mistral-7B-Instruct-v0.1 | 0.63 | 43.4 | 0.26 |
| GPT-4 | 0.61 | 43.1 | 0.44 |
| Platypus2-70B-instruct | 0.59 | 41.3 | 0.45 |
| Anthropic-claude-v1 | 0.57 | 36.1 | 0.34 |
| starchat-alpha | 0.56 | 35.8 | 0.33 |
| Mistral-7B-OpenOrca | 0.56 | 34.7 | 0.31 |
| llama-2-70b-chat | 0.54 | 31.6 | 0.31 |
| dolly-v2-7b | 0.53 | 35.4 | 0.37 |
| vicuna-13b-v1.5-16k | 0.53 | 37.8 | 0.46 |
| guanaco-13b | 0.52 | 34.4 | 0.42 |
| fastchat-t5-3b-v1.0 | 0.52 | 34.0 | 0.46 |
| dolly-v2-12b | 0.52 | 33.7 | 0.29 |
| chronos-hermes-13b | 0.52 | 35.4 | 0.48 |
| llama-2-13b-chat | 0.52 | 34.0 | 0.35 |
| GPT3.5-turbo | 0.51 | 35.4 | 0.45 |
| Koala-13B | 0.51 | 37.5 | 0.40 |
| llama-2-7b-chat | 0.51 | 31.6 | 0.22 |
| falcon-7b-instruct | 0.50 | 33.0 | 0.35 |
| vicuna-13b-v1.5 | 0.50 | 34.7 | 0.46 |
| RedPajama-7B-Chat | 0.50 | 32.3 | 0.35 |
| alpaca-7b | 0.50 | 34.0 | 0.49 |
| dolly-v2-3b | 0.50 | 32.3 | 0.24 |
| guanaco-7b | 0.50 | 33.3 | 0.42 |
| mpt-7b-chat | 0.50 | 31.2 | 0.21 |
| vicuna-7b-v1.5 | 0.49 | 31.2 | 0.20 |
| falcon-40b-instruct | 0.49 | 31.9 | 0.20 |
| GPT-NeoXT-Chat-20B | 0.49 | 33.3 | 0.36 |
| guanaco-65b | 0.49 | 33.0 | 0.21 |
| RedPajama-Chat-3B-v1 | 0.48 | 31.9 | 0.34 |
| Pythia-Chat-7B-v0.16 | 0.48 | 33.0 | 0.49 |
| Qwen-7B-Chat | 0.46 | 28.8 | 0.48 |
| Moral Permissibility Task Model |
AUC(↑) | Agg(↑) | MAE(↓) |
|---|---|---|---|
| GPT-4 | 0.74 | 41.9 | 0.31 |
| GPT3.5-turbo | 0.65 | 40.3 | 0.33 |
| falcon-7b-instruct | 0.64 | 43.5 | 0.29 |
| fastchat-t5-3b-v1.0 | 0.62 | 25.0 | 0.48 |
| GPT-NeoXT-Chat-20B | 0.61 | 36.3 | 0.37 |
| Anthropic-claude-v1 | 0.59 | 37.1 | 0.29 |
| Platypus2-70B-instruct | 0.57 | 26.6 | 0.41 |
| Mistral-7B-OpenOrca | 0.56 | 46.0 | 0.26 |
| dolly-v2-3b | 0.53 | 44.4 | 0.18 |
| RedPajama-7B-Chat | 0.53 | 42.7 | 0.21 |
| llama-2-7b-chat | 0.53 | 47.6 | 0.16 |
| RedPajama-Chat-3B-v1 | 0.52 | 39.5 | 0.28 |
| guanaco-13b | 0.52 | 34.7 | 0.28 |
| dolly-v2-7b | 0.52 | 33.9 | 0.39 |
| starchat-alpha | 0.52 | 37.9 | 0.31 |
| vicuna-13b-v1.5 | 0.52 | 38.7 | 0.36 |
| Mistral-7B-Instruct-v0.1 | 0.52 | 37.1 | 0.27 |
| llama-2-70b-chat | 0.51 | 46.8 | 0.17 |
| Koala-13B | 0.51 | 38.7 | 0.35 |
| vicuna-13b-v1.5-16k | 0.51 | 20.2 | 0.52 |
| guanaco-7b | 0.51 | 41.1 | 0.26 |
| alpaca-7b | 0.50 | 30.6 | 0.48 |
| mpt-7b-chat | 0.50 | 46.8 | 0.16 |
| vicuna-7b-v1.5 | 0.50 | 45.2 | 0.16 |
| falcon-40b-instruct | 0.50 | 46.8 | 0.16 |
| Qwen-7B-Chat | 0.50 | 25.0 | 0.45 |
| dolly-v2-12b | 0.48 | 38.7 | 0.26 |
| guanaco-65b | 0.48 | 42.7 | 0.20 |
| chronos-hermes-13b | 0.47 | 25.8 | 0.48 |
| Pythia-Chat-7B-v0.16 | 0.45 | 24.2 | 0.52 |
| llama-2-13b-chat | 0.42 | 39.5 | 0.25 |
Completion Models
| Causal Judgment Task Model |
AUC(↑) | Agg(↑) | MAE(↓) |
|---|---|---|---|
| GPT3.5-davinci-v3 | 0.67 | 41.3 | 0.41 |
| WizardLM-70B-V1.0 | 0.62 | 40.3 | 0.43 |
| GPT3.5-davinci-v2 | 0.61 | 37.8 | 0.31 |
| mpt-30b-instruct | 0.56 | 35.1 | 0.34 |
| LLaMA-2-7B-32K | 0.52 | 36.1 | 0.49 |
| pythia-12b-v0 | 0.52 | 34.7 | 0.37 |
| GPT3-curie-v1 | 0.51 | 36.8 | 0.37 |
| pythia-2.8b-v0 | 0.51 | 31.9 | 0.40 |
| pythia-6.9b | 0.51 | 34.4 | 0.36 |
| falcon-7b | 0.49 | 31.6 | 0.47 |
| Qwen-7B | 0.48 | 33.0 | 0.51 |
| Mistral-7B-v0.1 | 0.48 | 30.2 | 0.30 |
| falcon-40b | 0.48 | 33.0 | 0.45 |
| GPT3-babbage-v1 | 0.47 | 31.2 | 0.33 |
| mpt-30b | 0.45 | 31.6 | 0.26 |
| Moral Permissibility Task Model |
AUC(↑) | Agg(↑) | MAE(↓) |
|---|---|---|---|
| GPT3.5-davinci-v2 | 0.67 | 32.3 | 0.30 |
| GPT3.5-davinci-v3 | 0.61 | 20.2 | 0.51 |
| mpt-30b-instruct | 0.60 | 39.5 | 0.31 |
| pythia-2.8b-v0 | 0.58 | 37.1 | 0.35 |
| pythia-12b-v0 | 0.57 | 28.2 | 0.36 |
| falcon-40b | 0.55 | 35.5 | 0.35 |
| WizardLM-70B-V1.0 | 0.55 | 36.3 | 0.35 |
| mpt-30b | 0.55 | 46.0 | 0.19 |
| LLaMA-2-7B-32K | 0.52 | 25.0 | 0.50 |
| pythia-6.9b | 0.51 | 34.7 | 0.33 |
| Qwen-7B | 0.49 | 27.4 | 0.47 |
| falcon-7b | 0.48 | 32.3 | 0.35 |
| Mistral-7B-v0.1 | 0.47 | 45.2 | 0.23 |
| GPT3-curie-v1 | 0.45 | 26.6 | 0.39 |
| GPT3-babbage-v1 | 0.43 | 18.5 | 0.41 |
Implicit Alignment
In the previous section, we focus on analyzing aggregate metrics such as agreement over all stories. Such analysis often provides no information beyond comparing highly complicated systems with a single number. Since each of our stories is a combination of factors with corresponding attributes, we can leverage conjoint analysis and compute the Average Marginal Component Effect (AMCE) for each factor attribute, where AMCE reveals the implicit tendency of the underlying system when a particular attribute is present.
AMCE computes a score that indicates an implicit preference. We put the attributes of the same factor (e.g., Abnormal and Normal are the two attributes under factor “Event Normality”) on opposite sides – since the preference is over one attribute or the other. Each concentric circle is marked with a probability (e.g., 0.1), which represents the change in P(Yes) if the factor attribute had been present in the story. The implicit tendency is defined as the expected change in the probability of the system outputting Yes if this attribute had been present in the story. Intuitively, we can say a model has an implicit tendency for one attribute when it’s more likely to judge an event to be the cause, or the impending harm to be more morally permissible, if this attribute is present.
The radar plot shows not just the mean AMCE score, but the 95% confidence interval of the AMCE score. Since the AMCE score is the difference in probability change, if the upper/lower bound of the confidence interval crosses 0, it means the tendency is not statistically significant given the current data. The confidence interval is computed through Bootstrapping. If the 95% CI crosses 0, we report the maximal probable tendency towards one attribute (upper/lower bound on the AMCE).
- gpt-4
- gpt-3.5-turbo
- text-babbage-001
- text-curie-001
- text-davinci-002
- text-davinci-003
- claude-v1
- llama-2-7b-chat
- llama-2-13b-chat
- llama-2-70b-chat
- vicuna-13b-v1.5-16k
- vicuna-13b-v1.5
- Qwen-7B-Chat
- WizardLM_70B_V1dot0
- mpt-30b-instruct
- Mistral_7B_Instruct_v0dot1
- falcon-7b-instruct
- Platypus2-70B-instruct
We provide a summary of each model's alignment and misalignment with human implicit tendencies below. Note that we are only listing the alignment/misalignment if the AMCE score shows a significant tendency/preference in one attribute of a factor (95% confidence interval does not cross 0). The AMCE score we plot in the chart and report is the upper or lower bound on the 95% CI. We report this to signal maximal probable misalignment. Note this is different from a statistical significance test between the human and model tendencies. Use our code repo to conduct a statistical significance test.
If the human and model have implicit tendency in the same direction, we report the AMCE score in blue if the maximal probable difference is less than 10%. Otherwise, we report the score in red. If the human and model have the opposite implicit tendency, we report the AMCE score in red
Implicit Causal Judgment Tendencies
Implicit Moral Permissibility Tendencies
Factor Definitions
Factors Related to Causal Judgments
| Causal Factors | Definitions |
|---|---|
| Causal Structure | Wells & Gavanski, 1989; Mandel, 2003; Sloman & Lagnado, 2015 |
| Conjunctive | All events must happen in order for the outcome to occur. Each event is a necessary cause for the outcome. |
| Disjunctive | Any event will cause the outcome to occur. Each event is a sufficient cause for the outcome. |
| Agent Awareness | Samland et al., 2016; Kominsky & Phillips, 2019 |
| Aware | Agent is aware that their action will break the norm/rule or they know their action is “abnormal”. |
| Unaware | Agent is unaware or ignorant that their action will break the norm/rule, or they don’t know their action is “abnormal”. |
| Norm Type | Icard et al., 2017; N’gbala & Branscombe, 1995; Kominsky et al., 2015; Sytsma, 2021 |
| Prescriptive Norm | A norm about what is supposed to happen. |
| Statistical Norm | A norm about what tends to happen. |
| Event Normality | Knobe & Fraser, 2008; Hitchcock & Knobe, 2009; Alicke et al., 2011; O’Neill et al., 2021; Morris et al., 2019; Samland et al., 2016 |
| Normal Event | The event that led to the outcome is considered “normal”. |
| Abnormal Event | The event that led to the outcome is considered “abnormal/unexpected”. |
| Action or Omission | Ritov & Baron, 1992; Baron & Ritov, 2004; Henne et al., 2017, 2021; Clarke et al., 2015; DeScioli et al., 2011; Gerstenberg & Stephan, 2021 |
| Action as Cause | Agent performed an action that led to the outcome. |
| Omission as Cause | Agent did not perform the action, and the omission led to the outcome. |
| Time | Reuter et al., 2014; Henne et al., 2021 |
| Early | The event happened early. |
| Late | The event happened late. |
| Same Time | Multiple events happened at the same time. |
Factors Related to Moral Permissibility
| Factors | Definitions |
|---|---|
| Beneficence | Bloomfield, 2007; Christensen et al., 2014; Wiegmann et al., 2012 |
| Self-Beneficial | The agent themself benefits from their action. |
| Other-Beneficial | Only other people benefit from the agent’s action. |
| Personal Force | Christensen et al., 2014; Wiegmann et al., 2012 |
| Personal | Agent is directly involved in the production of the harm. |
| Impersonal | Agent is only indirectly involved in the process that results in the harm (e.g., using a device). |
| Counterfactual Evitability | Moore, 2008; Huebner et al., 2011; Christensen et al., 2014; Wiegmann et al., 2012 |
| Avoidable | The harm would not have occurred if the agent hadn’t acted. |
| Inevitable | The harm would have occurred even if the agent hadn’t acted. |
| Causal Role | Hauser, 2006; Christensen et al., 2014; Wiegmann et al., 2012 |
| Means | The harm is instrumental/necessary to produce the outcome. |
| Side Effect | The harm happens as a side-effect of the agent’s action, unnecessary to produce the outcome. |
| Locus of Intervention | Waldmann & Dieterich, 2007 |
| Instrument of Harm | The intervention is directed at the instrument of harm (e.g., the runaway train, the hijacked airplane). |
| Patient of Harm | The intervention is directed at the patient of harm (e.g., the workers on the train track). |
We also provide a full explanation of each factor in the Appendix of the paper.
Discussion
We summarize our high-level findings here:
- Non-monotonicity: The alignment to human biases does not necessarily increase with model size. We speculate that alignment is an area where the inverse scaling law applies (McKenzie et al., 2023).
- Heterogeneity: Interestingly, but perhaps not surprisingly, models that used the same training method and fine-tuned for human preferences do not have the same implicit tendencies. We highlight the difference between Claude-v1 and GPT3.5-turbo.
- Self-Tendency vs. Other-Preference: Humans are ego-centric and often make self-beneficial decisions. However, when asked to judge the behaviors of others, we prefer others to be altruistic. For example, in scenarios involving self-driving cars, Kallioinen et al. (2019) reported a stark contrast between what we tend to do versus what we want other people to do. This difference will make models trained on human preferences through RLHF different from how humans would tend to act in a given situation. As it is more prevalent to use LLMs as proxy humans for data labeling or experiments (Dillion et al., 2023; Gilardi et al., 2023), it is increasingly important to understand and measure these implicit differences.
Acknowledgments
Research reported in this paper was supported in part by a Hoffman-Yee grant and a HAI seed grant. We would like to thank Paul Henne for his assistance in curating high-impact causal reasoning literature. We thank Lucy Li for writing the ethical consideration section for this paper. We would also like to thank Jon Gauthier, Nicholas Tomlin, Matthew Jorke, Xuechen Li, Rose E Wang, and Dora Demszky for general discussions. An earlier version of the dataset was submitted to BigBench. We would like to thank the reviewers Marcelo Menegali, Adrià Garriga-Alonso, and Denis Emelin for their comments and feedback.
We thank May Khoo for data annotations and facilitation of labeling. We thank Simon Lee Huang for his work to run experiments with Automated Prompt Engineer and Social Simulacra.